

Excelには「重複の削除」という、非常に便利な機能がありますよね!

リストから重複しているデータを取り除くのなんて、ボタン一つで一瞬です。
でも…。
なんだか無性に関数だけで挑んでみたくなる時って、ありませんか?
この便利機能、関数だけで再現したらどうなるんだろう…?
…なんて考えちゃうのが筆者です。
そんなExcel好きなあなたに贈る、今回の暇つぶし企画!
今回のテーマは、
「A列に入力された果物リストから、重複の削除機能を使わずに関数だけで重複をなくしたリストを作る」
というものです。
え、普通に「重複の削除」使えばいいのでは…?
その通り!
実務ではそれが一番早いです(笑)
でも、今回はあえて関数だけで、
しかも色々なアプローチで考えてみるのが醍醐味。
普通にUNIQUE関数を使うだけじゃ、ちょっと物足りない!
そこで、あえて使える関数に制限を加えたり、
ちょっとトリッキーな関数の使い方を試してみたり…。
今回の目的は、
「Excel関数の組み合わせ方や数式の組み立て方への理解を深めること!」です。
「こんな方法でもできるんだ!」
「この関数、こんな使い方も…!」
こうした発見を通して、あなたのExcel関数力がさらにレベルアップする…かもしれませんよ?
もちろん、紹介する方法の中には「実務でこれ使う?」ってものも含まれます(笑)
ですが、一つのことを複数の方法で実現できると知っておくことは、
いざという時の応用力につながるはずです。
さあ、まずは空白のExcelシートを用意して、関数パズルの旅に出かけましょう!
今回のミッション
本記事では、Excel 2021を使用して検証および数式の作成を行っています。
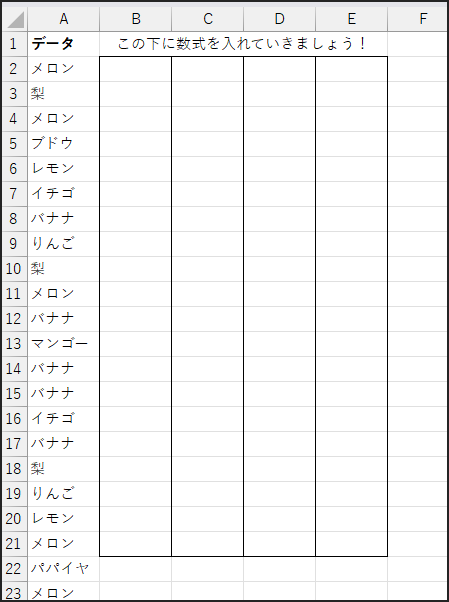
現在の状態とゴール
まず、現在の状態を確認します。
A列のA2セルからA61セルにかけて、
たくさんの果物の名前がランダムに入力されています(重複あり)

どんな果物がいくつあるかは、分からない状態です!
次に、目指すゴールです。
B列以降に、A列のリストから重複を取り除いた、
重複をなくしたリストを関数だけで作成します。
ルール:関数縛りでどこまでできる!?
今回の挑戦には、いくつかのルールがあります。
- 関数縛り: 使用するのはExcelの「関数」のみ!VBA(マクロ)は使いません。
- 段階的縛り: 方法が進むにつれて、使える関数に制限を加えていきます。どこまでできるか挑戦してみましょう!
- 順序不問: 表示される果物リストの順番は問いません。元リストと同じである必要はありません。
- エラー処理: 数式の結果がエラーになる場合は、空白(“”)を表示するようにします。リストの終わりを見やすくきれいに!
- 環境: Excel 2021で利用可能な関数を使用します。
データの準備
はじめに、空白のExcelシートを用意しましょう。
次に、A列のA2セルからA61セルまで、お好きな果物名を重複を含めて入力してください。
例えば、「りんご」「みかん」「りんご」「バナナ」のように、自由にデータを入れます。
今回はこのA列のリストを元に、B列以降に重複なしリストを作っていきます。
準備はいいですか?
それでは、頭の体操、スタートです!
方法1:最新関数で重複を削除! UNIQUE関数
考えかた
まずは、最新かつ最も一般的な方法からご紹介します。
Excel 2021 以降 / Microsoft 365 をお使いなら、
「UNIQUE関数」という、
まさにこのための関数が用意されています。
これを使わない手はありません!
この関数は、名前の通り、範囲内のユニークな(一意の)値を取り出してくれます。
さらに、「スピル」という機能によって、
必要な分のセルに自動で結果を展開してくれる、非常に便利なスグレモノです。
手順
数式入力
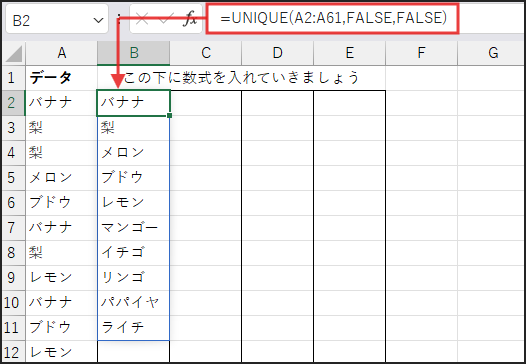
B2セルに以下の数式を入力します。そして、Enterキーを押すだけでOK!
=UNIQUE(A2:A61,FALSE,FALSE)
解説
このシンプルな数式のポイントを見ていきましょう。
UNIQUE関数の基本
UNIQUE関数は、=UNIQUE(配列, [比較方向], [回数]) のように使います。
まず、「配列」には、重複をチェックしたい範囲を指定します。
今回は元の果物リストである A2:A61 ですね。
次に、「比較方向」の引数は、省略するか FALSE を指定すると、行方向で比較します。
今回はこれでOKです。
TRUE だと列方向になります。
最後の「回数」の引数は、省略するか FALSE を指定すると、すべてのユニークな値を返します。
TRUE だとリスト内で1回だけ出現した値を返します。
今回は重複を除きたいので FALSE です。
スピル機能
UNIQUE関数は、Excel 2021以降の「スピル」機能に対応しています。
これは、数式が複数の結果を返す場合に、隣接するセルに自動的に結果が表示される機能です。
つまり、B2セルに数式を一つ入力するだけで、B3, B4… と必要なだけリストが自動で展開されます。

非常に便利ですね!
メリット&デメリット
メリット:
- 数式が非常にシンプルで分かりやすい。
- 入力は1つのセルのみ、スピル機能で自動展開。
デメリット:
- Excel 2021以降 または Microsoft 365 でないと利用不可。
方法2:定番テクニック! INDEX/MATCH/COUNTIF
考えかた
さて、ここからが関数パズルの本番です!
もし最新のUNIQUE関数が使えなかったらどうしましょう?
大丈夫です。
Excelには昔から使われている定番の組み合わせテクニックがあります。
それが INDEX関数、MATCH関数、COUNTIF関数の三銃士です!
考え方の流れは以下のようになります。
- まず、COUNTIF関数で、元リストの各要素が「既に抽出済みのリストに存在するか」をチェックします。
- 次に、MATCH関数を使って、「まだ抽出されていない要素」が元リストの何番目にあるかを探します。
- 最後に、INDEX関数で、見つけた番号に対応する元リストの値を取り出します。
数式を下のセルへコピーしていくことで、
重複しないリストを一つずつ抽出していきます。
手順
数式入力とコピー
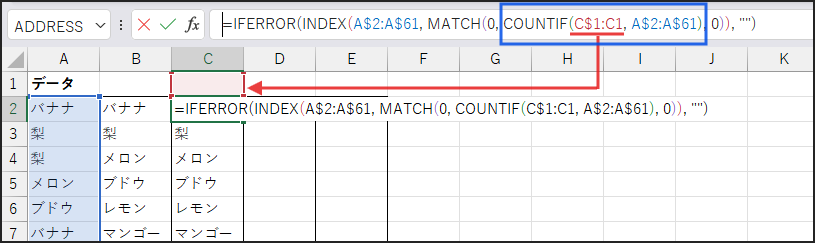
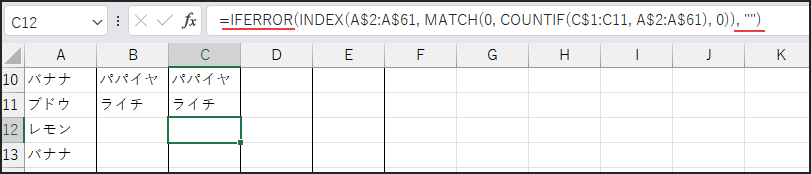
まず、C2セルに以下の数式を入力します。
=IFERROR(INDEX(A$2:A$61, MATCH(0, COUNTIF(C$1:C1, A$2:A$61), 0)), “”)

次に、Enterキーで確定した後、C2セルを選択します。
そして、フィルハンドル(セルの右下の小さい四角)をダブルクリックするか、
下方向にドラッグして、必要な範囲まで数式をコピーします。
解説
この数式は少し複雑に見えますが、分解して理解しましょう!
特に、$(絶対参照と複合参照)の使い方がポイントになります。
COUNTIF関数による重複チェック
数式の核となるのが COUNTIF(C$1:C1, A$2:A$61) の部分です。
まず、A$2:A$61 は元の果物リストです。
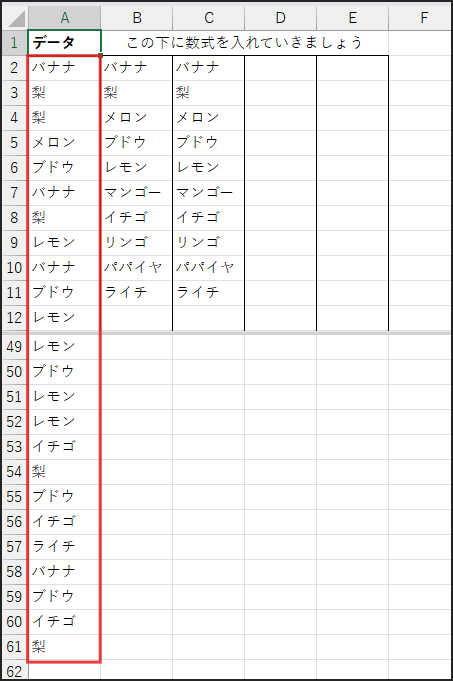
数式を下にコピーしても範囲が変わらないように、行番号を $ で固定しています。
次に、C$1:C1 は「既に抽出されたリスト」の範囲を指します。
C2セルに入力した時点では、見出し行である1行目のみ(C1セル)を参照しています。
これを下にコピーすると、参照範囲が C$1:C2, C$1:C3… と自動的に広がっていきます。
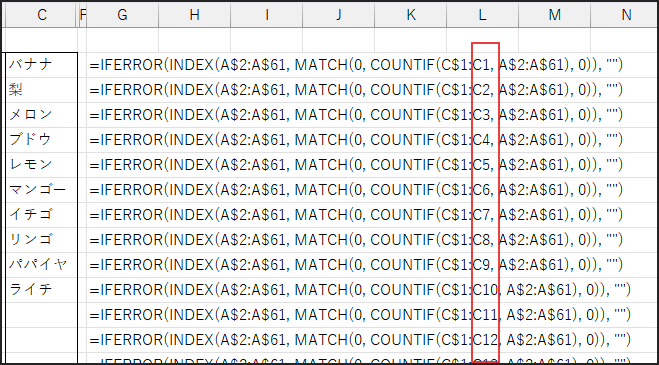
開始行の 1 は常に固定したいので $ を付けます。
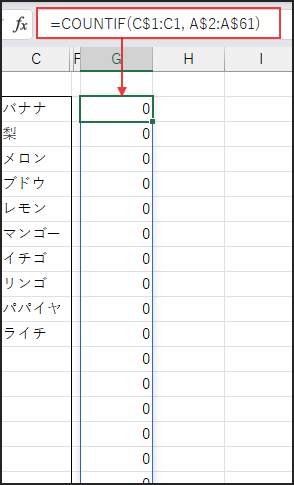
このCOUNTIF関数は、元リスト(A$2:A$61)の各要素が、
抽出済みリスト(C$1:C1など)にいくつ含まれているかを計算し、その結果を配列で返します。
例えば、まだ何も抽出されていないC2セルでは、すべて0が並んだ配列になります。
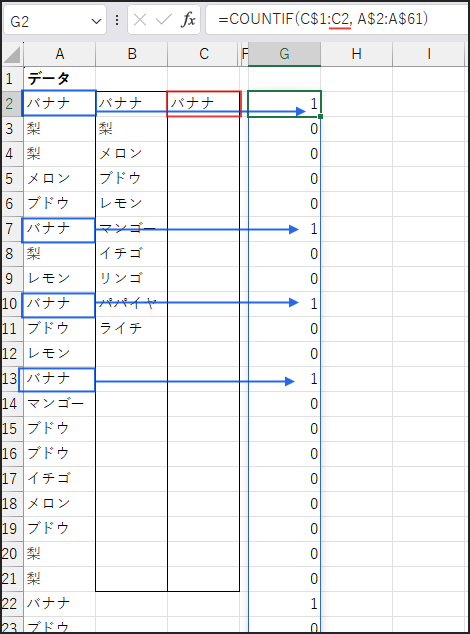
C3セルでは、C2セルで抽出された果物に対応する部分だけが1以上の値になります。
MATCH関数による未抽出要素の検索
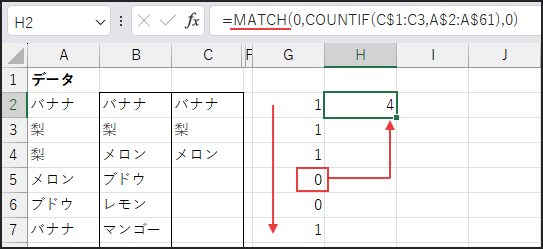
次に、MATCH(0, …, 0) の部分です。
これは、先ほどのCOUNTIF関数の結果(数値の配列)の中から、
最初に 0 が現れる位置を探します。
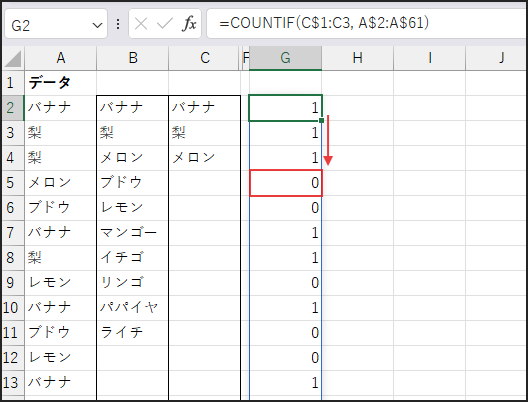
0 は「まだ抽出されていない」要素を示します。
末尾の引数 0 は、完全一致で検索することを意味します。
INDEX関数による値の取得
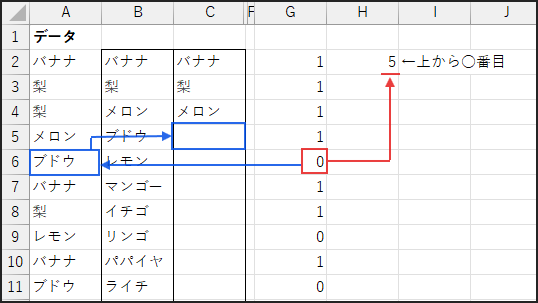
続いて、INDEX(A$2:A$61, …) です。
これは、MATCH関数で見つけた位置番号を使って、
元の果物リスト A$2:A$61 から対応する値(果物名)を取り出します。
IFERROR関数によるエラー処理
最後に、数式全体を IFERROR(…, “”) で囲んでいます。
全てのユニークな値を抽出し終わると、
MATCH関数は検索値の 0 を見つけられなくなり、
#N/Aエラーを返します。
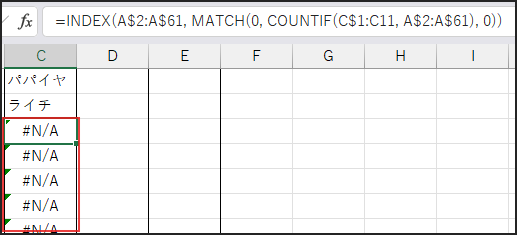
この場合に、IFERROR関数がエラーの代わりに空白 "" を表示させ、
リストの終わりをすっきりと見せる役割を果たします。
メリット&デメリット
メリット:
- 古いExcelバージョンでも利用可能。 (Excel 2007以降)
- 関数の組み合わせとしては比較的理解しやすい定番技術。
デメリット:
- 数式がやや長い、絶対参照・複合参照の理解が必要。
- データ量が多いと計算が重くなる可能性あり。
方法3:COUNTIF禁止!? MATCHとROWで乗り切る
考えかた
さらに縛りを厳しくしてみましょう!もし COUNTIF関数が使えなかったら?
「既に抽出済みかチェックする」という手段が使いにくくなりますね…。
でも、諦めるのはまだ早いです!
別の角度からアプローチしましょう。
重複を除いたリストを作るということは、
元のリストの中で「各要素が最初に出てきたものだけ」を拾い出せば良い、と考えられます。
そこで、MATCH関数を少し違う形で活用します。
まず、MATCH関数で、元リストの各要素が「リスト全体の中で最初に登場する行番号(のようなもの)」を取得します。
次に、ROW関数を使って、その要素の実際の行番号(のようなもの)を取得します。
そして、この二つの番号が一致するかどうかを比較します。
一致すれば、それは「その要素がリスト内で最初に現れた場所」である証拠です。
続いて、IF関数で、最初に現れた要素の行番号だけを抽出します。
さらに、SMALL関数とROWS関数を組み合わせて、抽出した行番号を小さい順(つまり元のリストの上から順)に取り出します。
最後に、INDEX関数を使って、取り出した行番号に対応する元の果物名を取得します。
少し複雑な手順になりますが、これでCOUNTIF関数なしでも目的を達成できるはずです!
手順
数式入力とコピー
まず、D2セルに以下の数式を入力します。
(Excel 2021以降なら通常Enterキーだけで配列数式として機能します。)
=IFERROR(INDEX(A$2:A$61, SMALL(IF(MATCH(A$2:A$61, A$2:A$61, 0)=(ROW(A$2:A$61)-ROW(A$2)+1), ROW(A$2:A$61)-ROW(A$2)+1), ROWS(D$2:D2))), “”)
その後、他の列と同様に、フィルハンドルを使って下方向に数式をコピーします。

解説
さあ、この難解に見える数式も、一つずつ紐解いていきましょう!
MATCH関数による初回出現位置の特定
まず、MATCH(A$2:A$61, A$2:A$61, 0) の部分です。
これは、元リスト(A$2:A$61)の各要素について、
それがリスト全体(A$2:A$61)の中で最初に現れるのが「何番目」かを計算し、配列で返します。
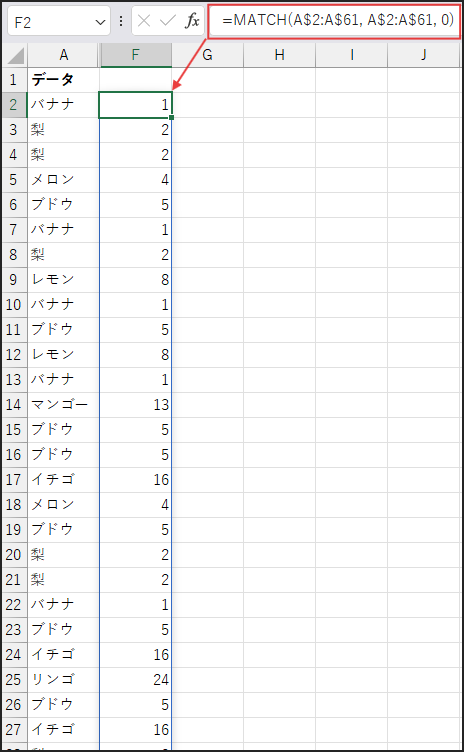
例えば、A列が「りんご, みかん, りんご」なら {1, 2, 1} という配列が生成されます。
ROW関数による相対的な行番号配列の生成
次に、ROW(A$2:A$61)-ROW(A$2)+1 の部分です。
これは、元リストの範囲に対応する連番(1, 2, 3, …)を配列で生成します。
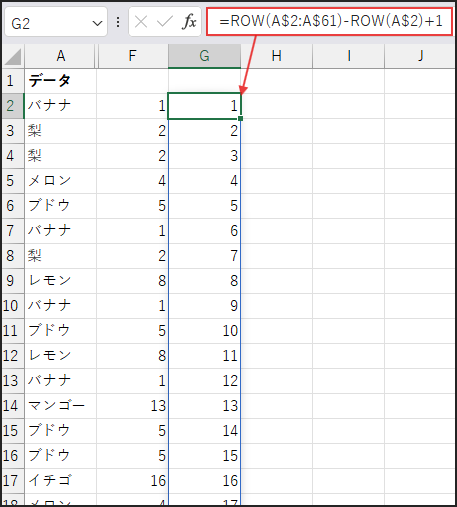
単純に ROW(A$2:A$61) とすると、実際の行番号である {2, 3, 4, ...} が返ってしまいます。
そこで、開始セルの行番号 ROW(A$2) (この場合は 2)を引いて、1 を足すことで、
範囲の先頭を 1 とする相対的な連番 {1, 2, 3, ...} を作っています。
IF関数による初登場要素の判定と比較
続いて、IF(MATCH(…) = ROW(…), ROW(…)) の部分です。
ここでは、先ほど作成した二つの配列(初回出現位置の配列と、相対的な行番号の配列)を比較します。
MATCH関数の結果とその要素の実際の順番が一致する場合、それはその要素が初めて登場したことを意味します。
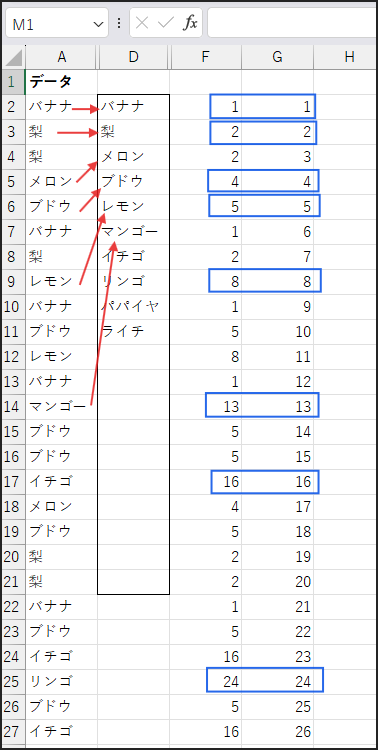
その場合は、その順番(ROW関数の結果)を返します。
一致しない場合(つまり重複している要素の場合)は、FALSE を返します。
例えば、{1, 2, 1} と {1, 2, 3} を比較すると、1番目と2番目は一致するので、結果は {1, 2, FALSE} のような配列になります。
SMALL関数とROWS関数による順番の取り出し
次に、SMALL(IF(…), ROWS(D$2:D2)) の部分です。
まず、ROWS(D$2:D2) は、数式が入力されているセル(例えばD2)からD2セルまでの行数を数えます。
D2セルでは 1、D3セルにコピーされると範囲が D$2:D3 となり 2、
D4セルでは D$2:D4 となり 3… というように、
下にコピーするごとに1ずつ増えるカウンターとして機能します。
そして、SMALL関数は、IF関数が生成した「初登場要素の順番」の配列(例:{1, 2, FALSE})の中から、
ROWS関数が返す数(1番目、2番目、3番目…)に該当する小さい値を取り出します。
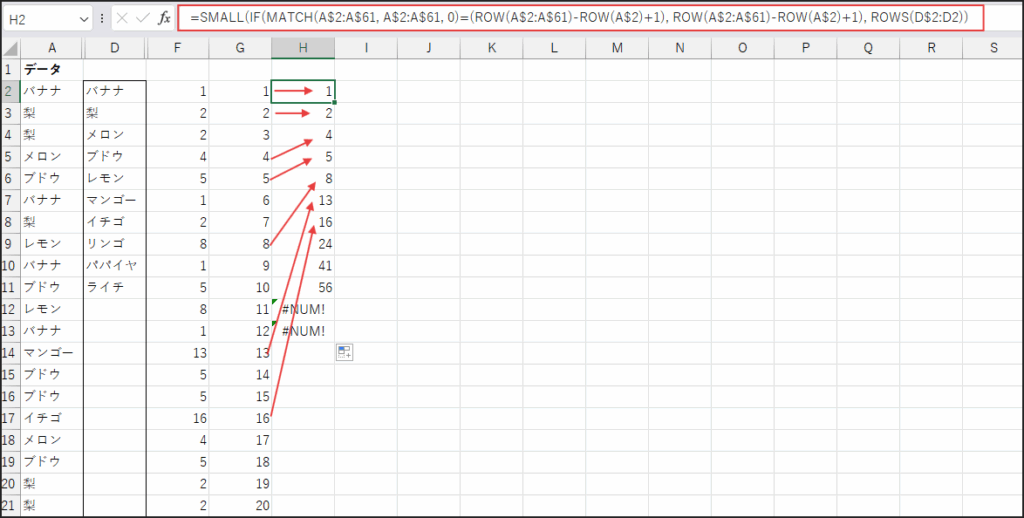
D2セルなら1番目に小さい 1、D3セルなら2番目に小さい 2 を取り出します。
INDEX関数による最終的な値の取得
最後に、INDEX(A$2:A$61, …) の部分です。
SMALL関数で取得した順番(元リスト内での相対的な位置)を使って、
元リスト A$2:A$61 から対応する果物名を取り出します。
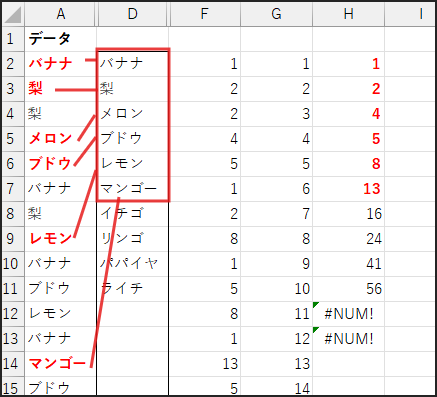
IFERROR関数によるエラー処理
これも同様に、すべてのユニークな値を抽出し終わると SMALL関数がエラーを返すため、
IFERROR関数で空白(””)を表示するようにしています。
メリット&デメリット
メリット:
- COUNTIF関数が使えない状況への対応策。
- 配列数式の考え方、MATCH/ROW関数の応用的な使い方の学習。
デメリット:
- 数式が非常に長く複雑、理解やデバッグが困難。
- 配列計算が多く、データ量次第で顕著に計算が重くなる。
方法4:INDEX/MATCHも禁止! LOOKUPの奥義?
考えかた
さあ、いよいよ最終問題です!INDEX関数もMATCH関数も使えないとしたら…?
これはかなり厳しい制約条件です。
主要なデータ抽出・検索関数が封じられてしまいました。
しかし! Excelにはまだ隠れた実力者、LOOKUP関数がいます。
LOOKUP関数については、LOOKUP関数の使い方!IFより簡単な条件分岐 でも紹介しています!

通常、LOOKUP関数は、検索範囲の中から特定の値以下の「最後のデータ」を見つけるのに使われますが、
この特性をうまく応用します。
今回は特別ルールとして、COUNTIF関数は使用可能とします。
INDEX/MATCH を封じ、さらにCOUNTIF も使用できないとなると、実現が極めて困難になります。
これにより、「まだ抽出されていない要素か?」のチェックは可能です。
具体的な手順は以下の通りです。
まず、COUNTIF関数で、元リストの各要素が「既に抽出済みのリストに存在するか」をチェックします。(結果は0か1以上)
次に、このチェック結果が 0 (まだ抽出されていない) かどうかを判定し、
TRUE / FALSE の配列を作ります。
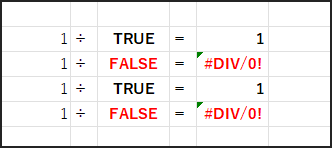
そして、この TRUE/FALSE の配列を逆数(1 / …)にします。
1/TRUE は 1、1/FALSE は #DIV/0! エラーになります。
続いて、LOOKUP関数の登場です。
検索値に、絶対に現れないであろう大きな値(ここでは例として 2)を指定します。
そして、先ほど作成した 1 か #DIV/0! の配列を検索範囲にします。
すると、LOOKUP関数は、検索範囲内の 2 以下の最後の数値、
つまり「配列内の最後の 1」を見つけ出します。
最後に、この「最後の 1」に対応する、
元の果物リスト (A$2:A$61) の値を結果として返します。
この一連の処理により、
実質的に「まだ抽出されていない要素のうち、元リストの中で一番下(最後)にあるもの」を取り出す、という動きになります。
なぜこの方法だけ抽出順序が異なる可能性があるのか?
LOOKUP(2, 1/(条件), 結果範囲) という使い方は、
条件を満たす最後の要素を返す特性があるためです。
元リストの下の方からチェックしていき、まだ抽出されていない要素が見つかった時点でそれを返す、というイメージです。
他の方法は、どちらかというと元リストの上から順に探していく動きでしたね。
手順
数式入力とコピー
まず、E2セルに以下の数式を入力します。
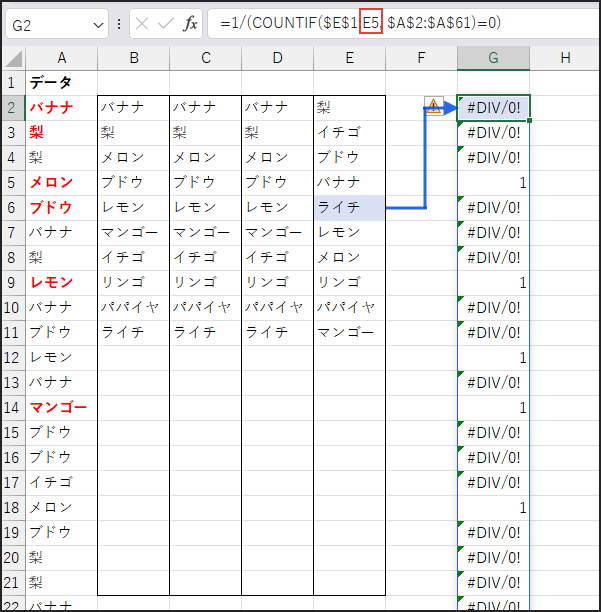
=IFERROR(LOOKUP(2, 1/(COUNTIF($E$1:E1, $A$2:$A$61)=0), $A$2:$A$61), “”)
入力後、他の列と同様に、下方向に数式をコピーします。
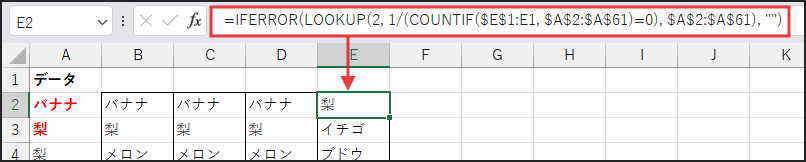
解説
この非常にトリッキーな数式も、ステップごとに見ていきましょう!
COUNTIF関数による未抽出判定
まず、COUNTIF($E$1:E1, $A$2:$A$61)=0 の部分です。
これは方法2と似ていますが、今回は抽出済みリスト $E$1:E1 に含まれていない(=0) かどうかを判定します。
結果として、元リストの各要素がまだ抽出されていない場合は TRUE、
既に抽出されている場合は FALSE となる配列が返されます。
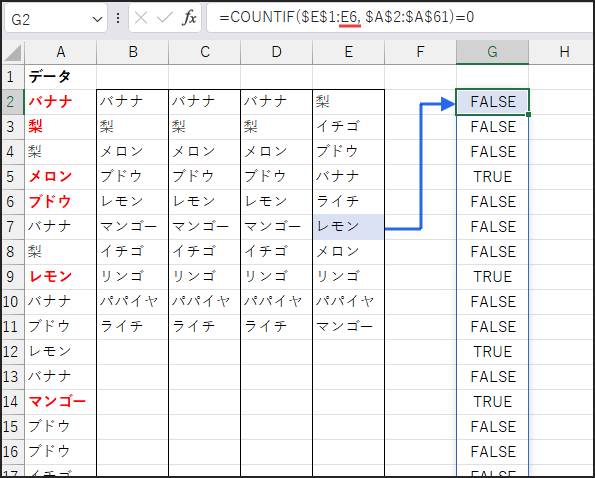
下にコピーすると、チェック範囲 $E$1:E1 が $E$1:E2, $E$1:E3… と広がっていきます。
逆数による検索用配列の作成
次に、1 / ( … ) の部分です。
先ほどの TRUE/FALSE 配列を逆数に変換します。
TRUE は数値として 1、FALSE は 0 として扱われるため、
1 / TRUE は 1、1 / FALSE はゼロ除算となり #DIV/0! エラーになります。
これにより、「まだ抽出されていない」要素の位置が 1、
そうでない位置がエラー値の配列ができます。
LOOKUP関数による最後の未抽出要素の検索
そして、核心部分である LOOKUP(2, …, $A$2:$A$61) です。
検索値に 2 を指定しています。

これは、検索範囲(1 か #DIV/0! の配列)には絶対に現れないであろう大きな値です。
1 より大きければ基本的に何でもOK!
検索範囲には、先ほど作成した 1 か #DIV/0! の配列を指定します。

結果範囲には、元の果物リスト $A$2:$A$61 を指定します。

LOOKUP関数は、検索値(2)以下の値を検索範囲(1 or エラー)から探し、見つかった最後の値(つまり最後の 1)に対応する「結果範囲」の値を返します。
これにより、「まだ抽出されておらず、元リスト内で最も下にある要素」の値が取得できるわけです。
IFERROR関数によるエラー処理
最後に、IFERROR(…, “”) で、すべてのユニークな値を抽出し終わり、
LOOKUP関数が該当する値を見つけられずにエラーを返す場合に、空白を表示させます。
メリット&デメリット
メリット:
- INDEX/MATCH関数が使えない制約下での対応策。
- LOOKUP関数の特殊だが強力な使い方の理解。
- COUNTIFが使えるため方法3より計算負荷が低い可能性。
デメリット:
- 数式が複雑で、直感的な理解が難しい。
- 抽出順序が他の方法と大きく異なる可能性。
参考:今回登場したExcel関数
今回の暇つぶしで登場した関数たちを軽くご紹介します。
- UNIQUE(配列, [比較方向], [回数]): 配列または範囲から一意の値のリストを返します。スピル対応。(Excel 2021以降/Microsoft 365)
- INDEX(配列, 行番号, [列番号]): テーブルまたは範囲内の指定された行と列にある値または参照を返します。
- MATCH(検査値, 検査範囲, [照合の種類]): 範囲内で指定された項目を検索し、その範囲内での相対的な位置を返します。
- COUNTIF(範囲, 検索条件): 指定された範囲内で検索条件に一致するセルの個数を返します。
- IFERROR(値, エラーの場合の値): 数式がエラーと評価される場合に指定した値を返します。エラーでない場合は、数式の結果を返します。
- SMALL(配列, k): データセットの中で k 番目に小さい値を返します。
- IF(論理式, 真の場合, [偽の場合]): 指定された条件が TRUE (真) か FALSE (偽) かを判定し、それに応じた値を返します。
- ROW([参照]): 参照の行番号を返します。
- ROWS(配列): 配列または参照内の行数を返します。
- LOOKUP(検査値, 検査範囲, [結果範囲]): ベクトル (1 行または 1 列の範囲) または配列から値を検索します。
普段あまり組み合わせない関数も、こうしてみると面白いですね!
まとめ
今回は、「重複を削除したリストを関数だけで作成する」という課題に、挑戦してみました!
まず、最新のUNIQUE関数を使えば一瞬で解決できることを見ました。
次に、あえてそれを使わずに、INDEX や MATCH, COUNTIF といった、
お馴染みの関数を組み合わせる定番の方法を確認しました。
さらに、COUNTIF すら縛って ROW や SMALL を駆使する方法や、
INDEX や MATCH まで封じられて LOOKUP 関数の少し変わった使い方で挑む方法まで、
合計4つのアプローチを試してみました。
結果として、どの方法でも目的の重複しないリストを作成できました!
特に方法4の LOOKUP の使い方は、普段あまり目にしないかもしれません。
「こんな風にも使えるんだ!」という発見があったのではないでしょうか。
正直、実務では素直に「重複の削除」機能か UNIQUE 関数を使うのがベストです(笑)
でも、こうやって「あえて違う方法でやってみる」「制限の中で工夫してみる」という思考は、
Excel関数の本質的な理解を深め、数式を柔軟に組み立てる力を養うのに役立つはずです。
「この計算はこの関数」と決め打ちせず、色々な引き出しを持っておくことで、
きっとあなたのExcelスキルはもっと豊かになります!
今回の暇つぶしが、みなさんのExcelライフのちょっとした刺激になれば幸いです!


