
はじめに:625文字の挑戦状!最頻出文字を探し出せ!
広大なExcelのセル範囲に、無数の文字が散らばっている…。
まるで、古代の暗号文か、はたまた星空のように。
今回のミッションは、この膨大な文字の宇宙の中から、たった一つ、最も多く輝く星(最頻出文字)を見つけ出すことです。
「え、そんなのCOUNTIFで地道に数えるしかないんじゃ…?
というか、作業列なしで、一つの数式だけで本当にできるの?」
そう思いますよね?
しかし、Excel関数の世界は、私たちが思うよりもずっと広く、深いのです。
今回の記事では、この難解なパズルを解くための、驚くべき4つのアプローチを紹介します。
それぞれ全く異なるロジックで答えにたどり着く、まさに「思考の冒険」です。
- アプローチ1:文字を「数字」に変える錬金術
- アプローチ2:最新関数で解く、現代の正攻法
- アプローチ3:力技で文字を繋げる、直感的な解法
- アプローチ4:文字の「住所」を特定する、超絶技巧ハック
この関数パズルを通して、あなたのExcelスキルは間違いなく新たな次元へと進化するでしょう。
さあ、準備はいいですか?
知的好奇心を満たす、壮大な旅に出発しましょう!
このテクニックは、アンケートの自由記述で一番多い意見を探したり、売上データから一番売れた商品名(文字)を探すのに使えます!
今回のミッション
本記事では、無料のWeb版Excelを使用して検証および画像の作成を行っています。Windowsはもちろん、MacやLinuxの方もブラウザさえあれば挑戦できます!
現在の状態: まず、ExcelシートのA1:Y25の範囲に、ランダムな「ひらがな」一文字がびっしりと入力されている状態です。(合計625文字!)

excel_de_himatsubushi067_sample.xlsx (WEB版のExcelファイルを開きます)
目指すゴール: このA1:Y25の範囲の中から、最も出現回数の多い文字を、たった一つの数式だけで、単一のセルに表示させます。

ルールと前提:
- 結果は、1つのセルに入力する1つの数式で求めること。
- 計算のための作業列は一切使用しないこと。
- 今回は、最も多く出現する文字は1種類だけであることが分かっている、という前提で進めます。
アプローチ1:UNICODE & MODE.SNGL(文字を「数字」に変える錬金術)
考えかた
最初に紹介するのは、まるで魔法のようにエレガントな方法です。
Excelには「最も頻繁に出現する値(最頻値)」を求めるための、その名もMODEという関数があります。
しかし、この関数には大きな弱点があります。
それは「数値しか扱えない」ということです。
そこで、発想を転換します。
「文字を、一時的にすべて『数字』に変えてしまえば、MODE関数が使えるのでは?」
この「文字と数字の相互変換」という錬金術のようなテクニックで、一気に答えを導き出します。
数式と解説
関数の詳細な仕様については、Microsoft公式のヘルプも参考にしてください。
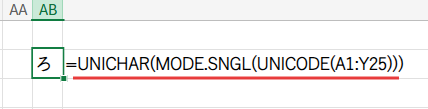
結果を表示したいセルに、以下の数式を入力します。
=UNICHAR(MODE.SNGL(UNICODE(A1:Y25)))
信じられないほどシンプルですね。
この数式は、3つの関数が見事な連携プレーを見せています。
内側の関数から、順を追って見ていきましょう。
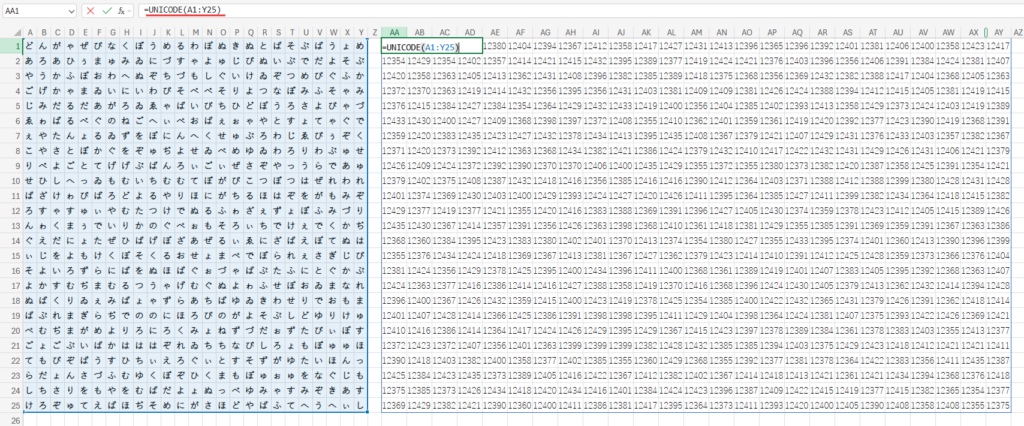
Step 1: UNICODE(A1:Y25) – 全ての文字を「固有の番号」に変換!
まず、UNICODE関数が登場します。
この関数は、引数に指定した文字に対応する「コードポイント」という固有の番号を返す、非常にシンプルな関数です。
例えば、=UNICODE("あ") は「12354」を、=UNICODE("い") は「12356」を返します。
この数式では、範囲A1:Y25全体を引数に指定しています。
すると、Excelは範囲内のすべてのセルにある「ひらがな」を、一括でこの「コードポイント」という数値に変換します。
結果として、メモリ上には元の範囲と全く同じ大きさの、「数値」の2次元配列が生成されます。
Step 2: MODE.SNGL(...) – 数字の中から「最頻値」を見つけ出す!
次に、MODE.SNGL関数(古いExcelではMODE関数)の出番です。
この関数は、数値の集まりの中から、最も出現回数の多い数値(最頻値)を探し出してくれます。
Step1で、すべての文字が数値に変換された巨大な配列ができましたね。
MODE.SNGL関数は、その数値の配列を引数に取り、最も頻繁に登場した数値を一つだけ返します。
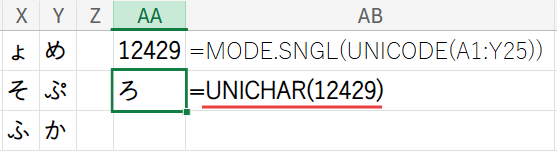
例えば、もし「ろ」という文字が最も多かった場合、そのコードポイントである「12429」が、この関数の結果として返されます。

Step 3: UNICHAR(...) – 「固有の番号」を文字に戻す!
最後の仕上げです。
UNICHAR関数は、先ほどのUNICODE関数と全く逆の働きをします。
引数に「コードポイント」の数値を指定すると、それに対応する文字を返してくれます。
Step2で得られた最頻値の番号(例:「12429」)をこの関数に渡すことで、見事に元の文字「ろ」が復元されます。
これで、目的の最頻出文字を特定することができました。
このアプローチは、数式が短く、古いバージョンから最新のExcelまで幅広く対応している、非常に優れた方法です。
UNICHAR関数、UNICODE関数については、ふりがな情報なしでもOK!Excelでひらがなをカタカナにする方法 にてテクニックを紹介しています!
アプローチ2:最新関数で解く、現代の正攻法
考えかた
次に紹介するのは、Microsoft 365やWeb版Excelで使える、最新の動的配列関数を駆使したアプローチです。
やっていることは非常に論理的で、まさに「正攻法」と呼ぶにふさわしい手順です。
- まず、2次元に散らばった625文字を、縦1列のリストに整列させます。
- そのリストから、重複を取り除いたユニークな文字リストを作成します。
- ユニークな文字リストの各文字が、元の範囲に全部で何個あるかを数え上げます。
- 数え上げた結果、最も多かった出現回数(最大値)を特定します。
- 最後に、「この最大値を持つ文字は何ですか?」と、リストに問い合わせて答えを得ます。
この一連のデータ処理を、関数の組み合わせだけで実現します。
数式と解説
結果を表示したいセルに、以下の数式を入力します。
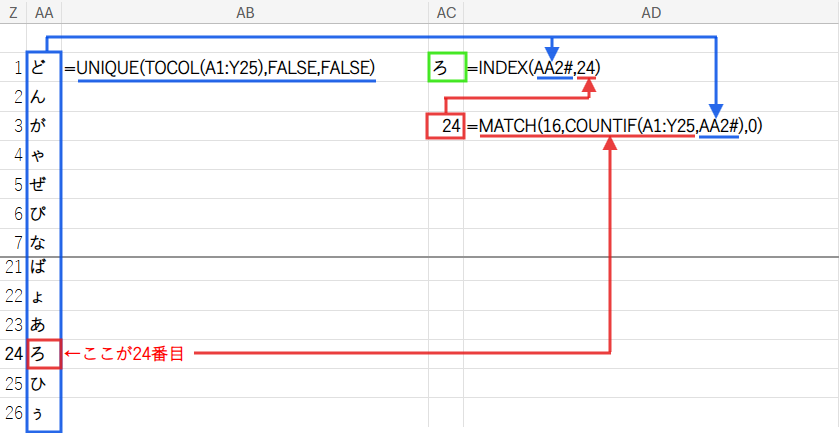
=INDEX(UNIQUE(TOCOL(A1:Y25),FALSE,FALSE),MATCH(MAX(COUNTIF(A1:Y25,UNIQUE(TOCOL(A1:Y25),FALSE,FALSE))),COUNTIF(A1:Y25,UNIQUE(TOCOL(A1:Y25),FALSE,FALSE)),0))

非常に長い数式ですが、これも分解すれば一つひとつの処理はシンプルです。
この数式は、同じ部品(UNIQUE(TOCOL(…))など)が複数回登場するのが特徴です。
まずは、登場する各関数の役割から見ていきましょう。
- TOCOL関数: Table to Columnの略。2次元のテーブル(表)を、縦1列の配列に変換します。
- UNIQUE関数: 配列の中から、重複しない値だけを抽出したリスト(配列)を返します。
- COUNTIF関数: 指定した範囲の中から、条件に合うセルの個数を数えます。
- MAX関数: 数値の集まりの中から、最も大きい値(最大値)を返します。
- MATCH関数: 検査値が、検査範囲の中で何番目にあるかを、その位置で返します。
- INDEX関数: 配列の中から、指定した位置にある値を取り出します。
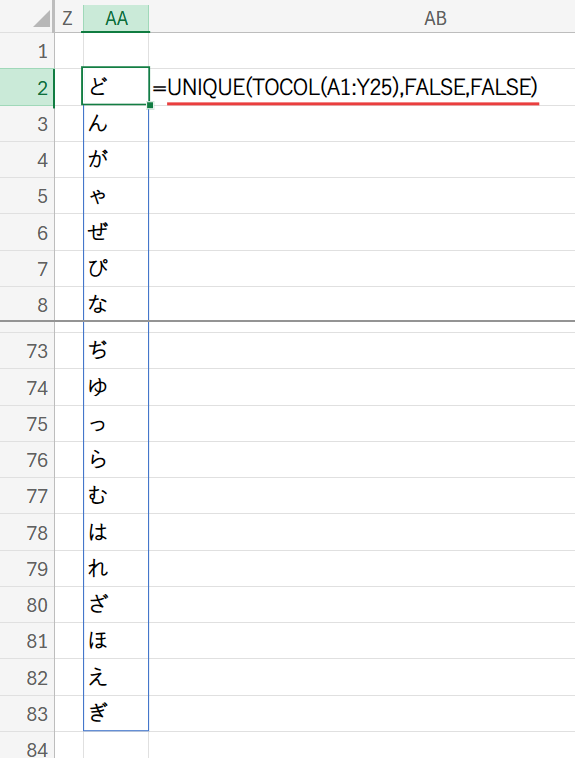
Step 1: UNIQUE(TOCOL(A1:Y25),FALSE,FALSE) – 重複しない文字リストの作成
数式の土台となる部分です。
ここで重要なのは、なぜTOCOL関数が必要なのか、という点です。
もし、UNIQUE関数を直接 =UNIQUE(A1:Y25) のように2次元範囲に使うと、Excelは「重複しない『行』」を探そうとします。
私たちがやりたいのは「重複しない『セル=文字』」を探すことなので、これでは意図した結果になりません。
そこで、まずTOCOL(A1:Y25)を使って、25×25の巨大な文字の範囲を、625行x1列の「縦長のリスト」に変換(整列)させます。
こうして1次元のリストにしてからUNIQUE関数に渡すことで、初めて個々の文字の重複を取り除くことができるのです。
この処理によって、「あ」「い」「う」…といった、この範囲に登場するすべての種類のひらがなを1つずつ並べた、綺麗なリストが生成されます。
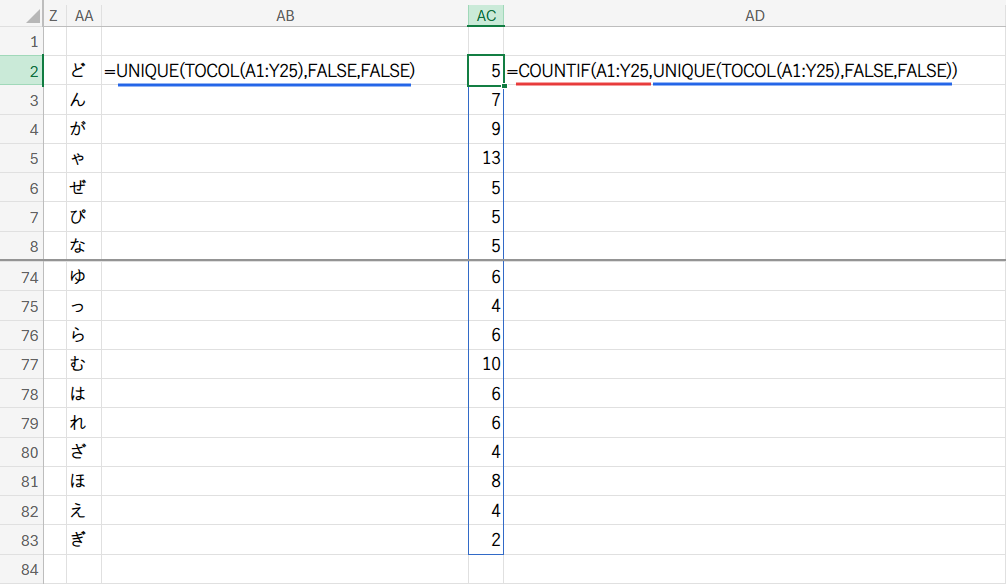
Step 2: COUNTIF(A1:Y25, UNIQUE(...)) – 各文字の出現回数を数える
次に、COUNTIF関数が登場します。
COUNTIF(検索範囲, 検索条件)という形で使いますが、ここでは検索条件にStep1で作った「ユニークな文字リスト」を丸ごと指定しています。
すると、Excelはユニークリストの各文字(”ど”, “ん”, “が”, …)が、元のA1:Y25の範囲にそれぞれ何個ずつあるかを、一気に計算してくれます。
結果として、ユニークリストと同じ行数の「出現回数の配列」がメモリ上に生成されます。(例:{5; 7; 9; …})
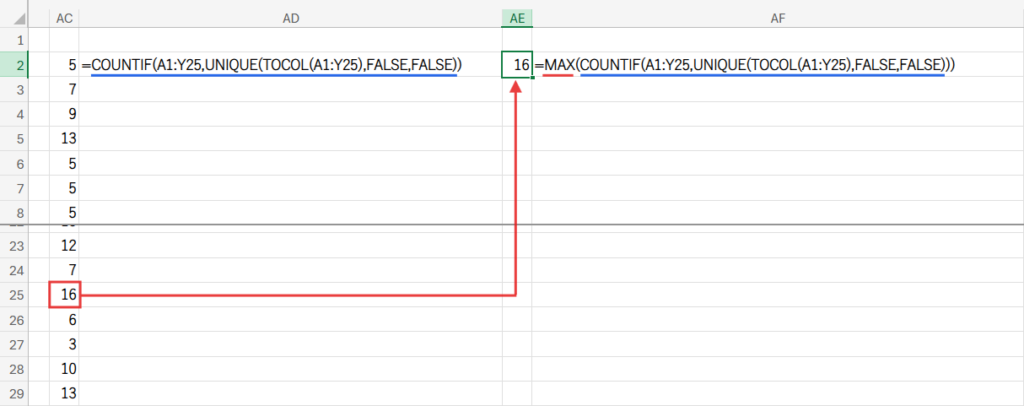
Step 3: MAX(...) – 最大出現回数の特定
このステップは非常にシンプルです。
MAX関数が、Step2で作成した「出現回数の配列」の中から、最も大きい数値、つまり最多出現回数を探します。
例えば、もし「ろ」が16回で最も多い場合、このMAX関数の結果は「16」になります。
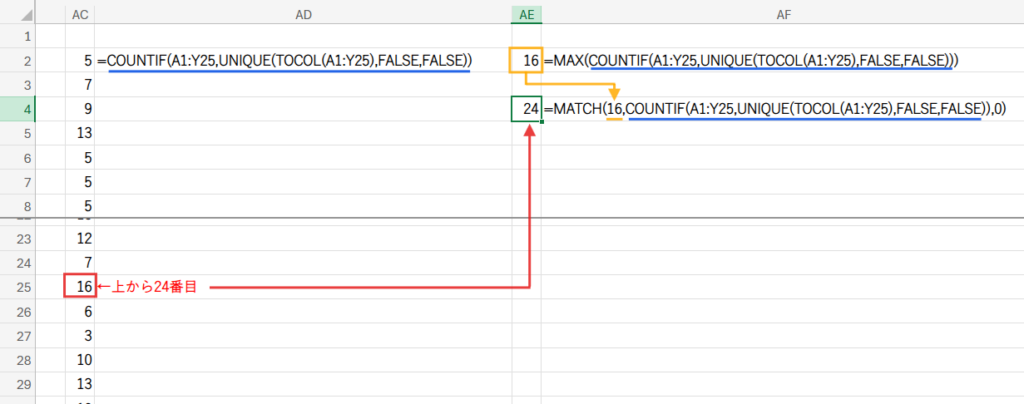
Step 4: MATCH(...) と INDEX(...) – 最頻出文字の特定
いよいよ最終段階です。
ここでは、Excelの定番コンビであるINDEX関数とMATCH関数が登場します。
まず、MATCH関数が「探し物」をします。
MATCH(探す値, 探す範囲, 0)という形で使い、探す値が範囲の何番目にあるかを探します。
- 探す値: Step3で見つけた最大出現回数(例:「16」)
- 探す範囲: Step2で作った「出現回数の配列」(例:{5; 7; 9; …})
- 0: 「完全一致」で探す、という意味です。
この結果、MATCH関数は「16」という数値が、出現回数の配列の「24番目」にあることを見つけ出し、「24」という位置番号を返します。
最後に、INDEX関数が、この位置番号を使って最終的な答えを取り出します。
INDEX(取り出す範囲, 位置番号)という形で使います。
- 取り出す範囲: Step1で作った「ユニークな文字リスト」(例:{“ど”; “ん”; “が”; …})
- 位置番号: MATCH関数が見つけた「24」
ユニークリストの「24番目」にある文字、つまり「ろ」が、最終的な答えとして表示される、というわけです。
アプローチ3:力技で文字を繋げる、直感的な解法
考えかた
3つ目の方法は、ロジックが非常に直感的で分かりやすいアプローチです。
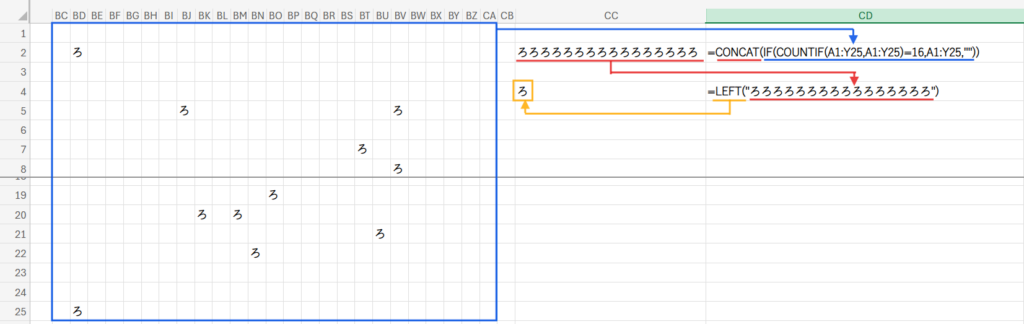
「最頻出の文字だけを抜き出して全部繋げた文字列を作ってしまおう!」という、ある意味、力技の解決策です。
出来上がった文字列(例:「ろろろろ…」)は、当然ながら最頻出文字だけで構成されています。
そのため、その文字列のどの部分を切り取っても答えは同じです。
今回は、関数としても意味的にも最もシンプルなLEFT関数を使って、先頭の一文字を取得します。
- まず、範囲内のすべての文字について、それぞれの出現回数を調べます。
- その中で、最も多い出現回数(最大値)を特定します。
- 出現回数が最大値と同じ文字だけを残し、それ以外は消してしまいます(空白にします)。
- 残った文字(=最頻出文字)を、全部連結して一つの長い文字列にします。
- その長い文字列の、先頭の一文字を取り出せば、それが答えです。
数式と解説
結果を表示したいセルに、以下の数式を入力します。
=LEFT(CONCAT(IF(COUNTIF(A1:Y25,A1:Y25)=MAX(COUNTIF(A1:Y25,A1:Y25)),A1:Y25,"")))
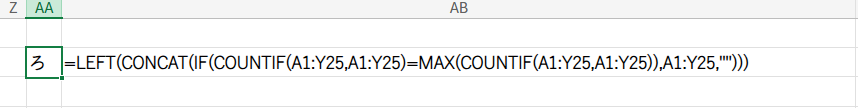
この数式も、内側から順に見ていきましょう。
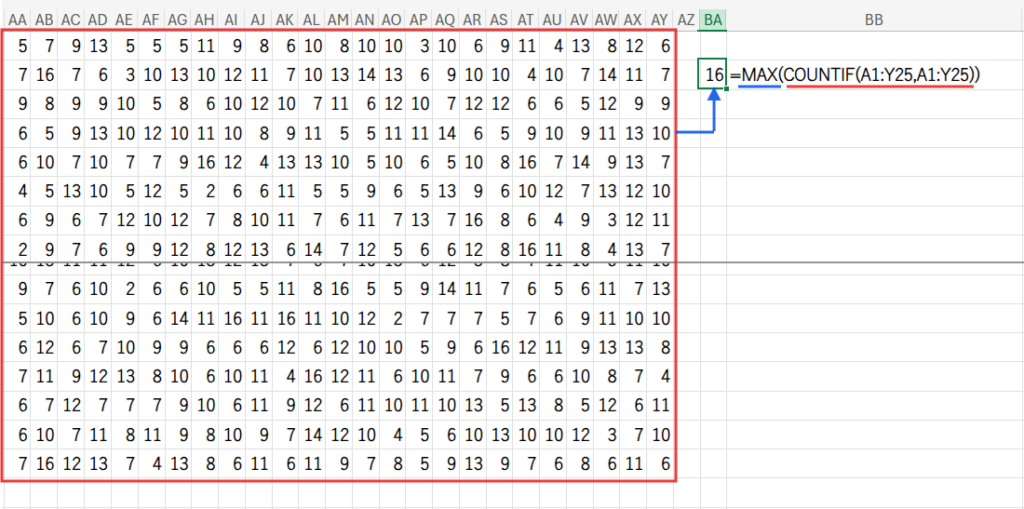
Step 1: COUNTIF(A1:Y25,A1:Y25) – 全セルの出現回数配列を作成
この数式の中で、最もトリッキーで重要な部分です。
COUNTIF関数の第1引数(検索範囲)と第2引数(検索条件)に、全く同じ範囲A1:Y25を指定しています。
このように使うと、Excelは範囲内の各セルについて、「そのセルと同じ値が、範囲全体にいくつあるか」を計算し、元の範囲と全く同じ大きさの「出現回数の2次元配列」を返します。
例えば、A1セルに「あ」があり、「あ」が全体で5個なら、結果の配列のA1セルの位置には「5」が入ります。

Step 2: MAX(COUNTIF(...)) – 最大出現回数の特定
MAX関数が、Step1で作成した巨大な「出現回数の2次元配列」の中から、最も大きい数値を一つだけ見つけ出します。
これが、今回のデータにおける最大出現回数(例:「16」)となります。
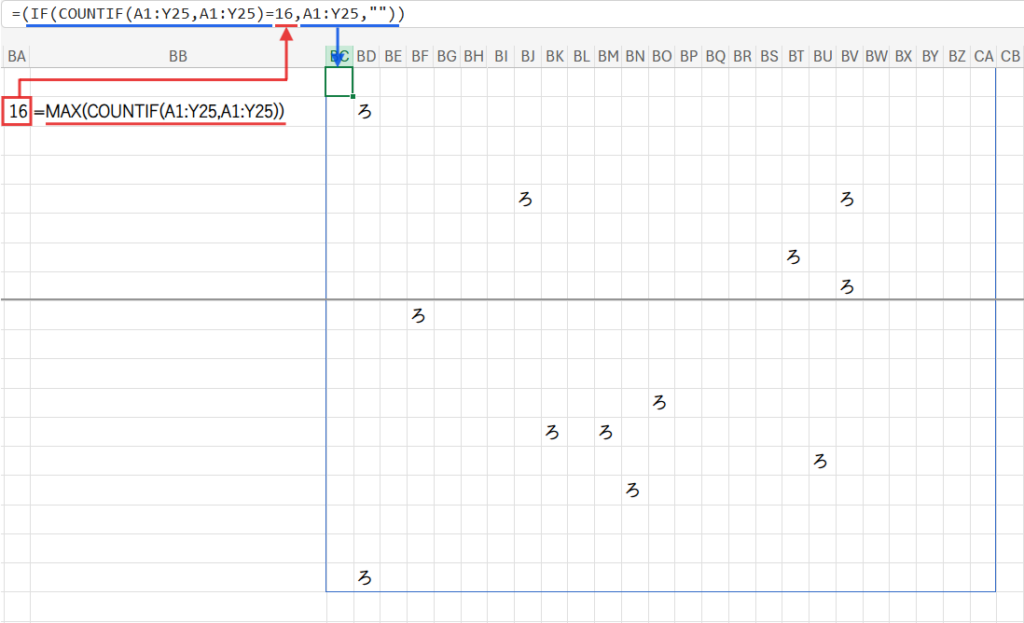
Step 3: IF(...) – 最頻出文字だけを残す
次に、IF関数がフィルタリングを行います。
IF(Step1の出現回数配列 = Step2の最大値, 元の文字配列, "")
これは、出現回数の配列の各セルの値が、最大値と等しいかどうかを判定します。
等しければ(つまり最頻出文字であれば)、元の文字を残します。
等しくなければ、空白(””)に置き換えます。
この結果、最頻出文字だけが残り、他のすべての文字が消えた2次元配列が生成されます。
Step 4: CONCAT(...) と LEFT(...) – 連結して取り出す
仕上げです。
CONCAT関数は、範囲内のすべてのセルの値を、順番に連結して一つの文字列にする関数です。
Step3で生成された「最頻出文字と空白だらけの配列」をCONCAT関数に渡すと、空白は無視され、最頻出文字だけが連結された文字列(例:「ろろろろろろろろろろろろ」)が作られます。
最後に、LEFT関数が、その文字列の左から1文字目を取り出します。
=LEFT("ろろろ...") となるので、結果はもちろん「ろ」ですね。
アプローチ4:文字の「住所」を特定する、超絶技巧ハック
考えかた
最後の方法は、これまでとは全く異なる視点から答えに迫る、最も技巧的なアプローチです。
この方法は、最頻出文字そのものを探すのではなく、「最頻出文字は、どのセルにいるのか?」という、その場所(住所=セル番地)を特定し、間接的にその中身を取り出します。
ロジックは非常に複雑ですが、古いExcel関数だけで構成されているため、互換性が非常に高いという特徴があります。
- まず、625個の各セルに、絶対に重複しない固有のID番号を割り振ります。
- 次に、アプローチ3と同じ方法で、最頻出文字がいるセルの場所だけを特定します。
- 特定した場所のセルのID番号を取得します。
- そのID番号を、数学の力で「行番号」と「列番号」に分解します。
- 分解した行・列番号から、セルの住所(例:”M12″)を文字列として作成します。
- 最後に、その住所のセルに「表札」を頼りに訪ねていき、中の文字を取り出します。
数式と解説
結果を表示したいセルに、以下の数式を入力します。
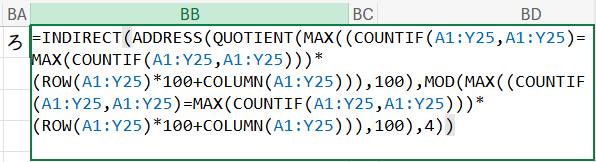
=INDIRECT(ADDRESS(QUOTIENT(MAX((COUNTIF(A1:Y25,A1:Y25)=MAX(COUNTIF(A1:Y25,A1:Y25)))*(ROW(A1:Y25)*100+COLUMN(A1:Y25))),100),MOD(MAX((COUNTIF(A1:Y25,A1:Y25)=MAX(COUNTIF(A1:Y25,A1:Y25)))*(ROW(A1:Y25)*100+COLUMN(A1:Y25))),100),4))
まさにラスボス級の数式ですね。
しかし、これも一つずつ分解していけば、必ずその仕組みを理解できます。
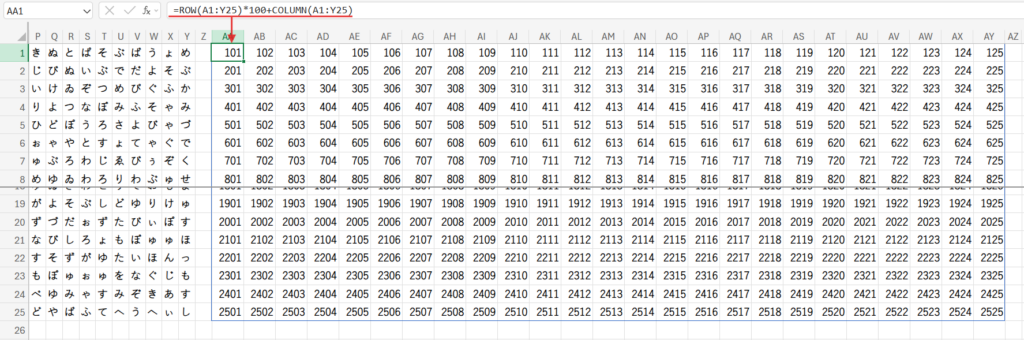
Step 1: ROW(A1:Y25)*100+COLUMN(A1:Y25) – 各セルに固有のIDを割り振る
この数式の根幹をなす、セルID生成パートです。
ROW(A1:Y25)は1~25の行番号の配列、COLUMN(A1:Y25)は1~25の列番号の配列を返します。
ここで、行番号に100を掛けてから列番号を足しています。
なぜ100を掛けるのか?
列は最大でも25列(Y列)までしかないので、行番号にそれより大きい100を掛けることで、IDが絶対に重複しなくなります。
- A1セル: 1 * 100 + 1 = 101
- B1セル: 1 * 100 + 2 = 102
- A2セル: 2 * 100 + 1 = 201
- Y25セル: 25 * 100 + 25 = 2525
このようにして、625個のセルすべてに、一意のID番号を持つ配列が作られます。
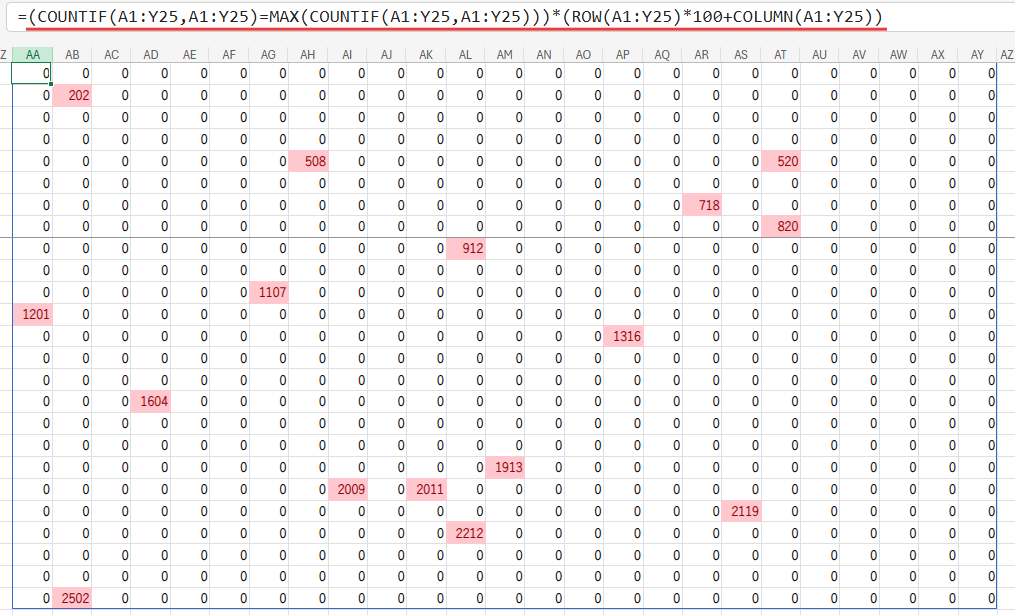
Step 2: (COUNTIF(...) = MAX(COUNTIF(...))) * (ID配列) – 最頻出文字のIDだけを残す
この部分は、アプローチ3の考え方と、Step1のID配列を組み合わせたものです。
(COUNTIF(A1:Y25,A1:Y25)=MAX(COUNTIF(A1:Y25,A1:Y25)))
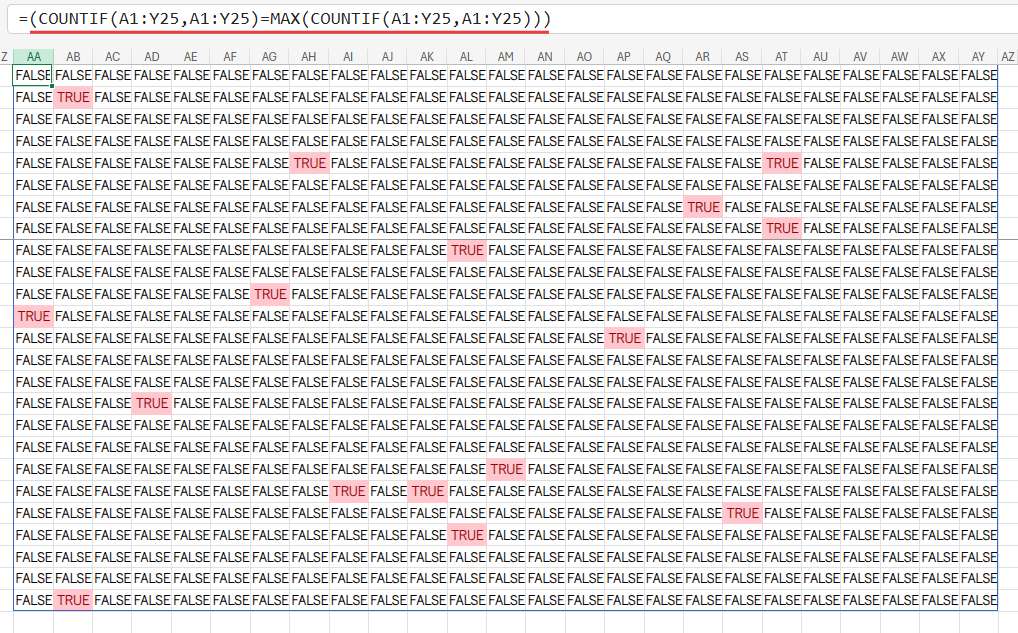
この部分が、最頻出文字のセルだけがTRUE、他はFALSEとなる、巨大な論理値の配列を生成します。
Excelでは、このTRUE/FALSEの配列に数値の配列を掛けると、TRUEは1、FALSEは0として計算されます。
つまり、「最頻出文字ではないセルのID」はすべて0になり、「最頻出文字であるセルのID」だけがそのまま残る、というわけです。
Step 3: MAX(...) – 目的のIDを一つに絞る
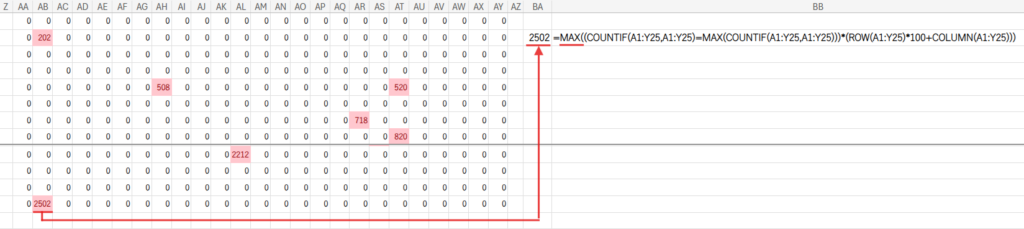
MAX関数が、Step2で生成された「IDと0だらけの配列」の中から、最も大きい値、つまり目的のID番号を一つだけ取り出します。
(最頻出文字が複数ある場合、最も右下のセルのIDが選ばれます)
Step 4: QUOTIENT(...) と MOD(...) – IDを「行・列番号」に分解
ここからが数学のパズルです。
Step3で得られたID番号(例:2502)を、元の行番号と列番号に戻します。
QUOTIENT関数は、割り算の「商(整数部分)」を求める関数です。
=QUOTIENT(2502, 100) は、「25」を返します。これは元の行番号ですね。
MOD関数は、割り算の「余り」を求める関数です。
=MOD(2502, 100) は、「2」を返します。これは元の列番号です。
見事に、ID番号を行と列に分解できました。

Step 5: ADDRESS(...) と INDIRECT(...) – 住所を頼りに文字を取り出す
最後の旅です。
ADDRESS関数は、行番号と列番号から、セルの住所を文字列として作り出す関数です。
=ADDRESS(25, 2, 4) は、「B25」という文字列を返します。(引数の4は、相対参照”$A$1″ではなく”A1″の形式にする、という意味です)
しかし、この時点ではまだただの「文字列」です。
そこで、最後の仕事人、INDIRECT関数の登場です。
この関数は、セル番地が書かれた文字列を、本物の「セル参照」に変換して、その中身を返してくれます。
=INDIRECT("B25") は、B25セルの中身、つまり目的の最頻出文字「ろ」を最終的に表示してくれるのです。

まとめ
今回は、「大量の文字の中から最頻出文字を探す」というテーマで、4つの全く異なるアプローチを探求しました。
- アプローチ1 (UNICODE): 発想の転換でエレガントに解く、最もスマートな方法。
- アプローチ2 (最新関数): 現代のExcelのパワーをフル活用する、論理的で分かりやすい正攻法。
- アプローチ3 (CONCAT): 力技で文字を連結する、ロジックが直感的な方法。
- アプローチ4 (ADDRESS): 関数の特性を極限まで利用し、互換性を保ちながら解く超絶技巧。
特にアプローチ4のような数式は、実務で書く機会はまずないでしょう(笑)。
しかし、こうした関数パズルに挑戦することは、一つひとつの関数の役割や特性を深く理解し、それをどう組み合わせれば問題を解決できるかという「論理的思考力」を鍛える、最高のトレーニングになります。
普段何気なく使っている関数たちが、組み合わせ次第でこれほどまでに強力なツールになるということを、感じていただけたのではないでしょうか。
今回の挑戦が、皆さんのExcelライフをより豊かにする、知的な刺激となれば嬉しいです。
- 条件付き書式の魔術!Excelのセルで「7セグメント時計」を完全再現
- ドロップダウンリストは遅い!Excelで爆速入力を実現する2つの代替案
- 【難問】Excelで0と1の2次元配列から「連続する塊」を数える数式
- Excelで重複なし・誤認なしの安全なクーポンコードを大量生成する数式
- Excel数式に游ゴシックは使うな!「Consolas」でミスを根絶する最強設定


