
はじめに:「ひらがな」を「カタカナ」にしたい!
Excelで名簿やリストを管理しているとき、こんな場面はありませんか?
「この列に入力されている『ひらがな』の部分だけ、全部『カタカナ』に一括変換したい!」
Excelに詳しい方なら、「ふりがな」を扱うPHONETIC関数を思い浮かべるかもしれません。
=PHONETIC(A1)
しかし、これには大きな「罠」があります。
「あれ? Web版Excelだと、漢字がそのまま返ってくる…」
「ローカル版でも、ふりがな情報のないセルだと、何も変わらない…」
そうなんです。
要するに、PHONETIC関数は、セルに「ふりがな情報」が(入力時などに)設定されていないと正しく動作しません。
そして、Web版Excelでは、この「ふりがな情報」が自動で生成・読み取りされないため、期待通りに動かないのです。

じゃあ、どうするのか?
諦める?…いいえ!「Excelで暇つぶし」の読者の皆さんは、そんなことで諦めませんよね?
今回の記事は、このPHONETIC関数に一切頼らず、純粋な関数のロジックだけで、「ひらがな」を「カタカナ」に(ついでに「カタカナ」を「ひらがな」に)変換する、超絶技巧の関数パズルです!
実用性はさておき(笑)、このロジックの背景にある「文字コード」の仕組みを理解することは、あなたのExcelスキルを確実にレベルアップさせます。
例えば、「A」から「Z」までのアルファベット配列を数式一発で作成する、なんていう応用もできるようになりますよ!
=UNICHAR(SEQUENCE(,26,65))
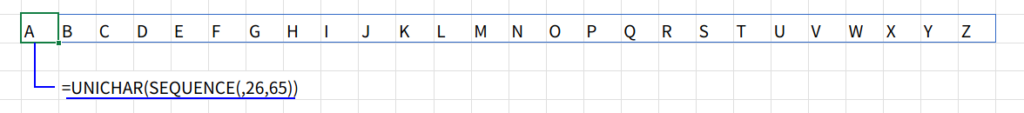
本記事では、無料のWeb版Excelを使用して検証および画像の作成を行っています。Windowsはもちろん、MacやLinuxの方もブラウザさえあれば挑戦できます!
ステップ1:冒険の準備 – 変換する文字列
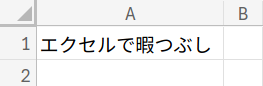
何事も、まずは準備から。まっさらなシートのA1セルに、変換したい文字列を入力します。
今回は、例として「エクセルで暇つぶし」と入力してみましょう。
ゴールは、この文字列を「エクセルデ暇ツブシ」という、ひらがなだけがカタカナに変換された文字列にすることです。
ステップ2:最大のカギ、「文字コード」とは?
関数の詳細な仕様については、Microsoft公式のヘルプも参考にしてください。
早速ですが、今回の最大のカギは、「文字コード」です。
「文字コードって何?」
簡単に言えば、「コンピュータが文字を識別するために使っている、固有の番号」のことです。
普段、私たちは「あ」や「A」を文字として認識していますが、コンピュータはそれらをすべて「番号」として扱っています。
Excelには、この文字と番号を相互に変換する、2つの便利な関数が用意されています。
・UNICODE(文字): 文字を「文字コード(数値)」に変換します。
例: =UNICODE("あ") → 12354
例: =UNICODE("ア") → 12450

・UNICHAR(数値): 文字コード(数値)を「文字」に変換します。
例: =UNICHAR(12354) → あ
例: =UNICHAR(12450) → ア
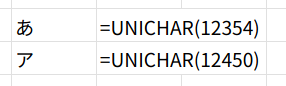
ここで、何か気づきませんか?
「あ」(12354) と「ア」(12450)。その差は、12450 - 12354 = 96 です。
「い」(12356) と「イ」(12452)。その差は、12452 - 12356 = 96 です。
そう!ひらがなとカタカナは、文字コードが例外なく「96」だけズレて並んでいるのです!
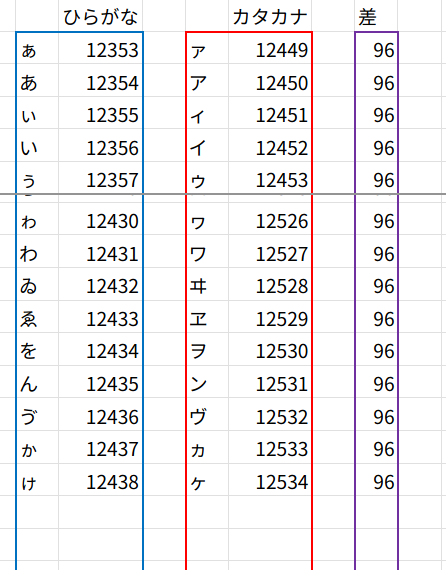
つまり、今回のミッションは、「文字列を1文字ずつバラバラにし、その文字コードが『ひらがな』の範囲だったら『96』を足す」というロジックで解けることが分かりましたね!
ミッション1:「ひらがな」を「カタカナ」に変換せよ!
考えかた
では、数式を組み立てます。
可読性を上げるため、最新のLET関数を使って、処理を「a」という名前の変数に一時保存しながら進めます。
数式と解説
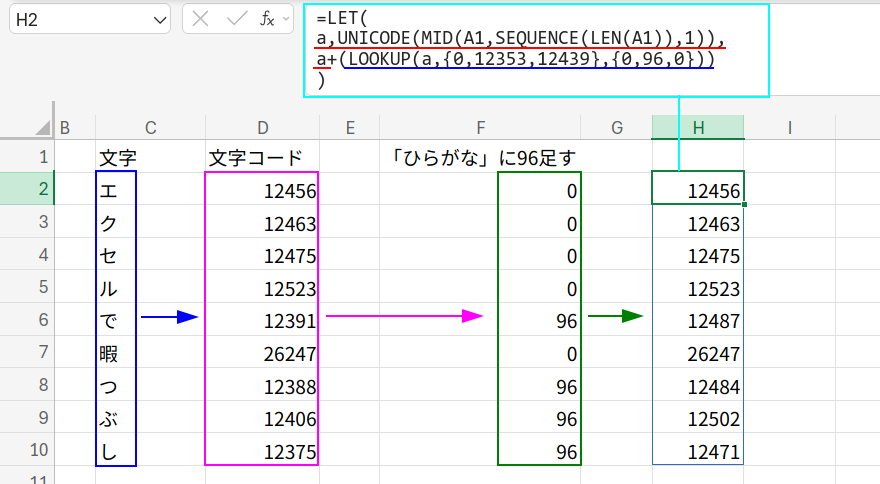
=LET(a,UNICODE(MID(A1,SEQUENCE(LEN(A1)),1)),CONCAT(UNICHAR(a+(LOOKUP(a,{0,12353,12439},{0,96,0})))))
この数式、LET関数によって2つのステップに分かれています。
ステップ1: 文字列を分解→文字コードへ
a,UNICODE(MID(A1,SEQUENCE(LEN(A1)),1))
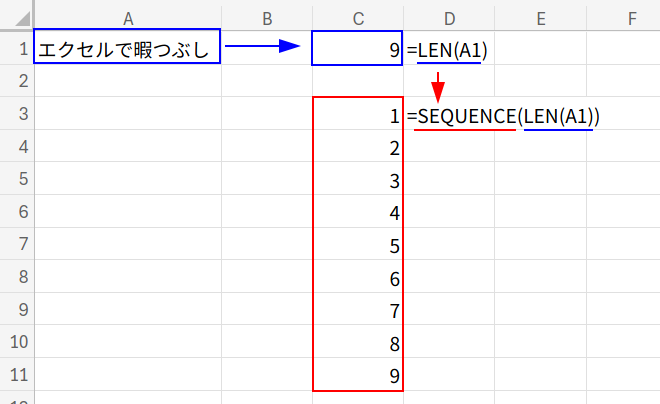
・LET(a, ...): まず、LET関数(=LET(名前1, 値1, 計算式))を使い、これから行う計算結果に「a」という名前を付けます。
・LEN(A1): 文字列「エクセルで暇つぶし」の長さ「9」を計算します。
・SEQUENCE(LEN(A1)): SEQUENCE(9)となり、{1;2;...;9}という縦の連番配列を生成します。
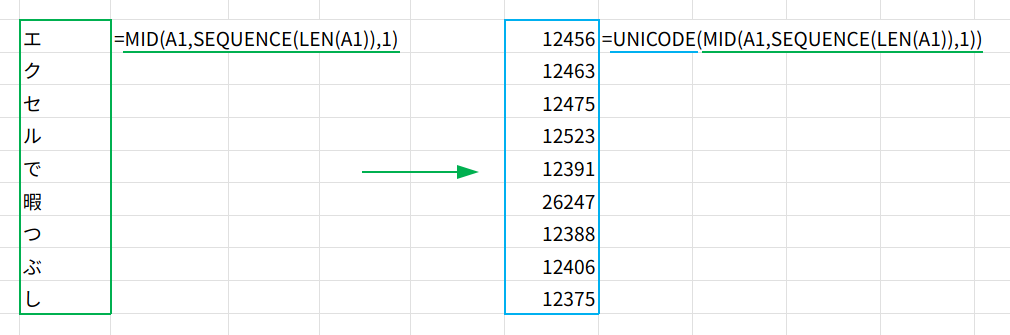
・MID(A1, ..., 1): MID関数とSEQUENCE関数を組み合わせる、定番のテクニックです。
A1の文字列を、1文字目から1文字、2文字目から1文字…と順番に抜き出し、{"エ";"ク";"セ";"ル";"で";"暇";"つ";"ぶ";"し"}という、1文字ずつの配列に分解します。

・UNICODE(...): そして、分解した文字の配列を、UNICODE関数で一括して文字コードの配列に変換します。
これが変数「a」の中身({12456;12463;...;12375})となります。
ステップ2:ひらがなの文字コードに96を足して文字に戻す
CONCAT(UNICHAR(a+(LOOKUP(a,{0,12353,12437},{0,96,0}))))
ここが計算の本体です。
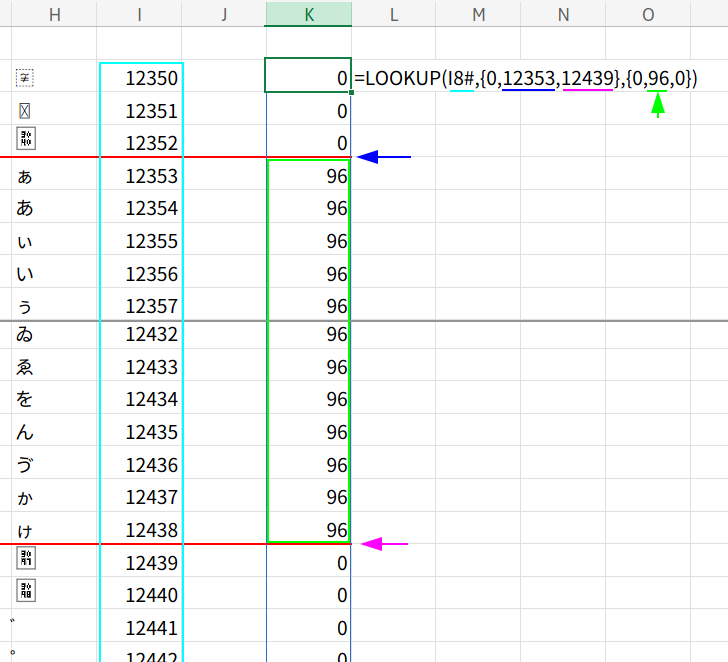
・LOOKUP(a,{0,12353,12437},{0,96,0}): ここがロジックの核心!
LOOKUP関数を使って、条件分岐を行います。

- 検索値:
a(ステップ1で作った文字コードの配列) - 検査範囲:
{0, 12353, 12437}(ひらがなの範囲「ぁ」(12353)~「ん」(12435)の前後の境界値) - 対応範囲:
{0, 96, 0}(足したい数値)
LOOKUP関数(近似一致)は、検索値以下の最大値を探します。
つまり…
- 「0~12352」(ひらがなより前)の文字コードは、0が選ばれ、「0」を返します。
- 「12353~12438」(「ぁ」~「ゕ」の範囲)の文字コードは、12353が選ばれ、「96」を返します。
- 「12439~」(「ゕ」より後)の文字コードは、12439が選ばれ、「0」を返します。
この方法、IF関数を何度もネストするより、はるかに短く、スマートに条件分岐ができますよね!
・a + ...: ステップ1の元の文字コード配列「a」に、このLOOKUPが返した「加算する数値」(0 または 96)の配列を足し合わせます。
ひらがなの文字コードだけが+96され、カタカナの文字コードに変換されます。
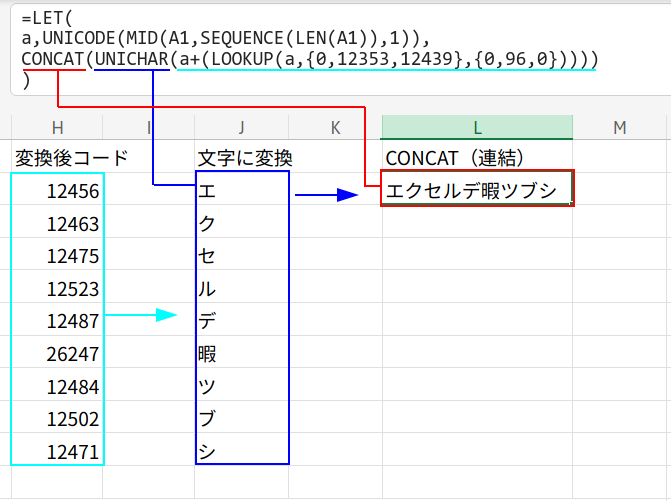
・UNICHAR(...): 変換後の文字コード配列を、UNICHAR関数で再び文字の配列に戻します。{"エ";"ク";"セ";"ル";"デ";"暇";"ツ";"ブ";"シ"}
・CONCAT(...): 最後に、CONCAT関数が、バラバラだった文字の配列を一つの文字列に連結し、「エクセルデ暇ツブシ」の完成です!
古くからあるLOOKUP関数をこの時代にあえて使ってみたい!と思ったら以下の記事を是非ご覧ください!

ボーナスミッション:「カタカナ」を「ひらがな」に変換せよ!
ここまで理解できたあなたなら、もうお分かりですね?
逆の「カタカナ→ひらがな」変換は、LOOKUP関数の数値を変えるだけです!
A1セルに「エクセルデ暇ツブシ」と入力されているとして…
数式と解説
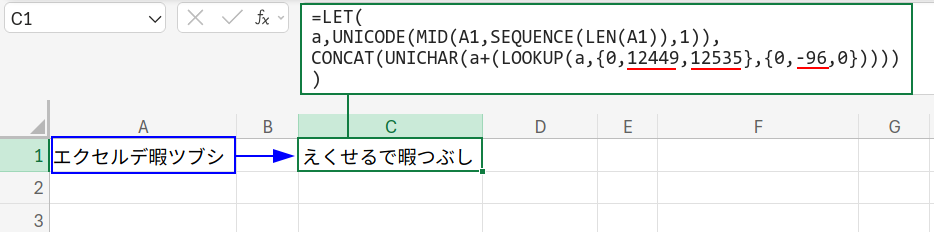
=LET(a,UNICODE(MID(A1,SEQUENCE(LEN(A1)),1)),CONCAT(UNICHAR(a+(LOOKUP(a,{0,12449,12535},{0,-96,0})))))
・LOOKUP(a, {0,12449,12535}, {0,-96,0}): ロジックは全く同じです。
- 検索範囲をカタカナの範囲(「ァ」(12449)~)に変更。
- 戻り配列を「-96」(引く)に変更。
つまり、カタカナの文字コードだけが-96され、ひらがなに変換されます。
すなわち、結果は「えくせるで暇つぶし」ですね!
まとめ:文字コードは、関数の「共通言語」だ!
今回は「ひらがな⇔カタカナ」変換を紹介しました。
Excelの「文字コード」という非常に重要な基本原理を学ぶ、良いきっかけになったのではないでしょうか。
実用性は…まあ、あまりないかもしれませんが(笑)、この「文字コード」という「関数の共通言語」を知っておくことは、あなたの発想力を間違いなく豊かにします。
例えば、「A」から「Z」までのアルファベット配列を、=UNICHAR(SEQUENCE(26,,65))という数式一発で作れるようになるのも、この文字コードの知識があってこそなのです。
今回の関数パズルが、皆さんのExcelへの知的好奇心をさらに深めるきっかけになれば、これほど嬉しいことはありません。

