

はじめに:壮大なプロジェクトの集大成
山本式和音番号の探求、その長きにわたる論理構築も、いよいよ一つの大きな目的地に到着します。
↓↓↓最初の記事です。まだの方は是非↓↓↓

前回までの記事で、長調・短調それぞれにおける和音の「構成パーツ」を導出する、無数の精緻な数式を一つずつ組み立ててきました。
和音の「役割」から「コードネーム」への最終変換
今回の目的は、これまでに生成した全てのパーツを統合し、最終的なコードネームを完成させること。
そして、これまでの努力の結晶である数式群を、最高のパフォーマンスを発揮する「静的なマスターデータベース」へと昇華させることです。
この記事は、単に最後の数式を解説するだけではありません。
私たちが構築してきたこの複雑なシステムを、いかにして実用的で、かつ信頼性のあるツールとして「完成」させるか、その設計思想の全体像を解き明かす、シリーズの集大成となります。
STEP1:短調データベースの完成と「エラー処理」の哲学
まず、短調データベースの最後のピースを埋め、コードネームを完成させます。
そして、このシステム全体に貫かれている、エラーに対する重要な考え方に触れます。
AL列「コード」の最終数式(短調編)
優先順位で表示を制御するIFS関数
短調データベース(DB_山本式和音_mollシート)のAL2セルに、以下の数式を入力します。
=IFS(M2=”x“,“”,AK2<>“”,AK2,TRUE,TEXTJOIN(“”,TRUE,Q2:AJ2))
この数式は、長調編(第17回記事)で解説したものと全く同じロジックです。
↓↓↓詳細はこちらです↓↓↓

IFS関数を司令塔として、①M列の「x」フラグ(不使用和音)、②AK列の「直接入力」、③TEXTJOINによる「自動連結」という明確な優先順位で、最終的なコードネームの表示を制御します。
このロジックが長調・短調で共通であることは、山本式和音番号の体系的な一貫性を示しています。
なぜエラーを放置するのか?「#REF!」は敵ではない、道しるべである
あえてIFERRORを使わない、という設計思想
ここまでの作業で、データベースには#REF!や#スピル!といったエラー値が、至る所に表示されているはずです。
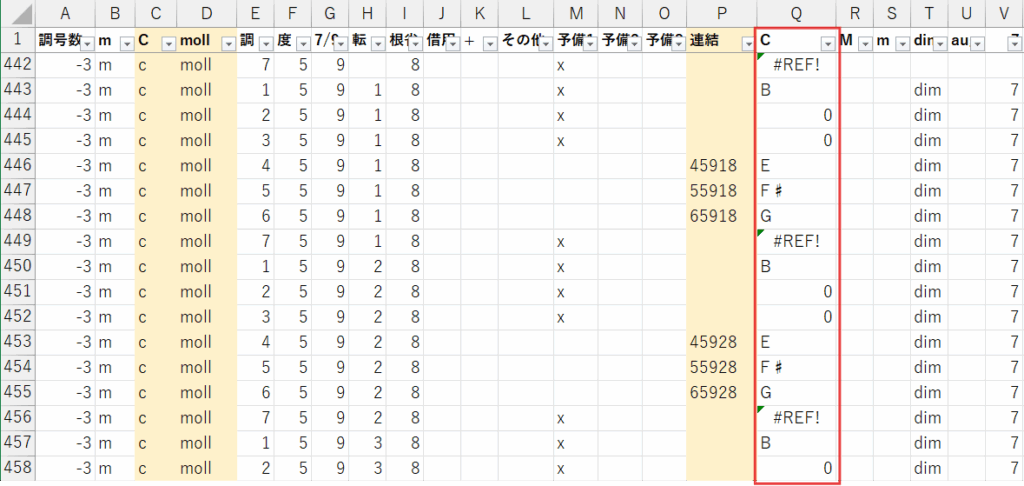
なぜ、これらのエラーをIFERROR関数などで隠し、見た目を綺麗にしないのでしょうか?
それには、実務においても非常に重要となる、明確な理由があります。
例えば、#REF!というエラーは、「参照先が見つからない」ことを示しています。
これは、入力した山本式和音番号の組み合わせが、システムのルール上「使用しない和音」である可能性や、あるいは参照元である音階表のデータ入力に誤りがある可能性を示唆してくれます。
もし、これをIFERROR関数で全て空白にしてしまうと、どこで問題が起きているのか分からなくなり、原因の特定が非常に困難になります。
「エラーは、システムが私たちに送ってくれる重要なメッセージである」と捉え、その原因を追求できるようにしておくこと。
見た目の美しさにこだわりすぎて、システムの透明性を損なわないようにする、という実務的な判断なのです。
STEP2:マスター参照表の作成 – Excelを「ジェネレーター」として使う
さて、長調・短調すべてのコードネーム生成ロジックが完成しました。
しかし、このままではINDIRECTやOFFSETといった「揮発性関数」を多用しているため、ファイルの動作が重くなりがちです。
ここからは、このファイルを「データ生成機(ジェネレーター)」として捉え、最終成果物である「静的なマスター参照表」を作成します。
長調・短調データの統合と「値貼り付け」
数式をなくし、高速で安定したデータベースを構築する
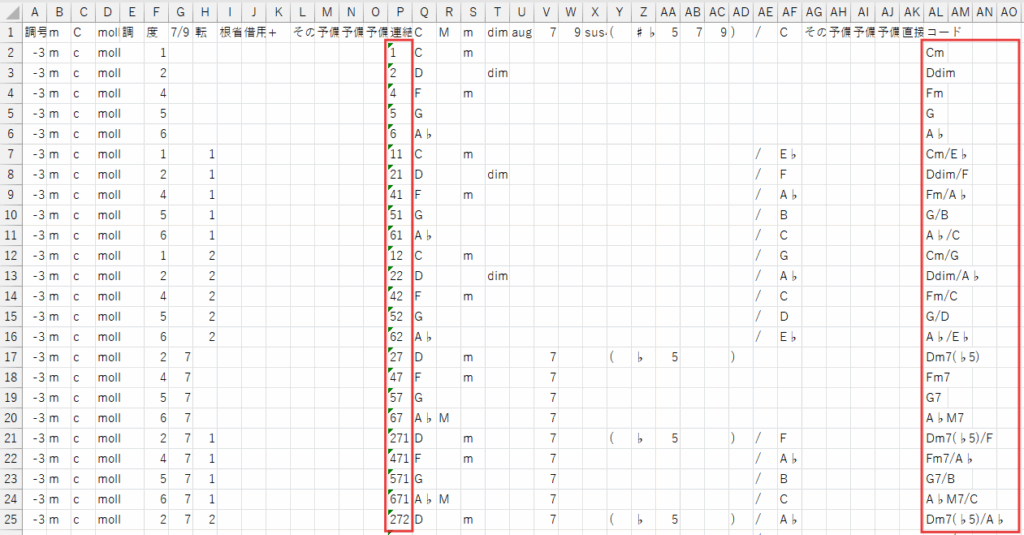
以下の手順で、計算結果である「値」だけを、新しいブックにコピーしていきます。
- まず、新しいExcelブックを一つ開いてください。これが、最終的なマスターデータベースとなります。
- 次に、長調のデータベース(DB_山本式和音)に戻り、フィルター機能を使ってAL列の空白行を非表示にします。
- A列からAL列まで、ヘッダー行を含めた全ての表示されているデータ範囲を選択し、コピー(Ctrl+C)します。
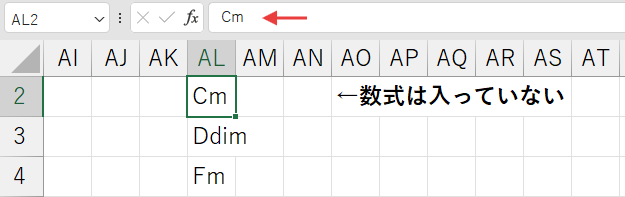
- そして、新しいブックのA1セルを選択し、右クリックから「形式を選択して貼り付け」→「値」を選んで貼り付けます。これにより、数式ではなく、計算結果の「値」だけが貼り付けられます。
- 続けて、短調のデータベース(DB_山本式和音_moll)でも同様にフィルターをかけてデータをコピーし、新しいブックの長調データのすぐ下の行に、同じく「値」として貼り付けます。
この作業により、全ての数式が取り除かれ、高速で安定した、巨大な「山本式和音番号とコードネームの対応表」が完成します。
すべての調を1つのシートに貼り付けます。
なぜ「値のみ」にするのか?揮発性関数とパフォーマンス
なぜ、このような手間をかけて「値のみ」のデータベースを作成するのでしょうか。
その最大の理由はパフォーマンスの向上です。
INDIRECTやOFFSETといった揮発性関数は、ブック内で何か変更があるたびに再計算が実行されるため、多用するとExcelの動作を著しく重くします。
しかし、一度完成した「和音のルール」は、今後変更されることはありません。
つまり、このデータベースは、一度作ってしまえば、常に計算し続ける必要のない「静的な参照データ」なのです。
したがって、数式を値に変換することで、動作の重さから解放され、今後の分析ツールとして利用する際に、極めて高速なレスポンスを実現できるのです。
まとめ:システムの「思想」を理解し、その真価を解放する
このシリーズを通じて、山本式和音番号という壮大な体系を、Excelというツールで具現化してきました。
その過程は、単なる数式の組み立てではありませんでした。
- 数式で生成できる部分は効率的に自動化する。
- 数式化が困難な部分は「直接入力」で補う、実用的な判断。
- デバッグのしやすさを考慮し、エラーをあえて「見せる」設計。
- そして最後に、パフォーマンスを最大化するために、動的な数式を「静的な値」へと変換する。
この「ハイブリッドな設計思想」こそが、複雑なシステムを構築し、実用的なツールとして完成させるための、最も重要な知恵と言えるでしょう。
さて、完璧で、高速で、信頼性の高い「和音のマスターデータ」が完成しました。
次回の記事では、いよいよこのデータベースを活用し、ユーザーが任意の和音番号を入力すれば、瞬時にコードネームが表示される、実用的な「検索・変換ツール」の構築に取り掛かります。
プロジェクトは、分析から「活用」のフェーズへと移ります。
お楽しみに!


